I tend to trend on Clusters the most.


VMs and Resource Pools have soft limits so they are the easiest and
quickest to change.
Want to know when you’ll run out of capacity?
– The hardware
is the limit
– Trend hardware
utilization
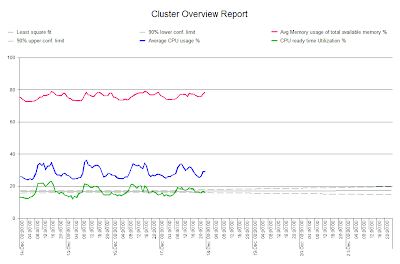
The
graph below shows a trend on 5 minute data for average CPU and shows a nice
flat trend.

If I take the same data and trend on the peak hour then I see a
difference.

You can see that the trend has a steady increase, the peaks are getting
larger.
When trending ensure that you trend to cope with the peaks, to deliver
immediate value, as these are what you will need to deal with.
Aggregating the Data
Next let’s look at aggregating the data. Previously we looked at Ready Time and as I said Ready Time is accumulated against a virtual machine but you can aggregate this data to see what is going on in the Cluster as a whole.
Next let’s look at aggregating the data. Previously we looked at Ready Time and as I said Ready Time is accumulated against a virtual machine but you can aggregate this data to see what is going on in the Cluster as a whole.
In the example below CPU utilization is not that busy but there is a
steady increase in Ready Time.

The dynamic may be changing and new VM’s that are being created have
more CPU’s, which could eventually cause a problem.
I hope you've enjoyed the series and for more VMware white papers and on-demand webinars join our Community and get free access to some great resources.
http://www.metron-athene.com/_resources/login.asp
Phil Bell
Consultant
















